데이터 매핑
데이터 이동을 위한 청사진으로서의 데이터 매핑
팀에서 시스템 간에 데이터를 이동할 때 실패는 일반적으로 복사본 자체에서 시작되지 않습니다.
각 소스 필드가 대상 모델에 어떻게 배치되어야 하는지 명확하게 설명할 수 없을 때 시작됩니다.
데이터 매핑은 이러한 문제를 해결합니다.
한 스토리지 시스템 또는 형식에서 다른 스토리지 시스템으로 값을 이동하는 방법을 자세히 정의하여 ETL 작업과 마이그레이션 도구가 예측 가능하게 작동하도록 합니다.
데이터 매핑의 핵심 개념
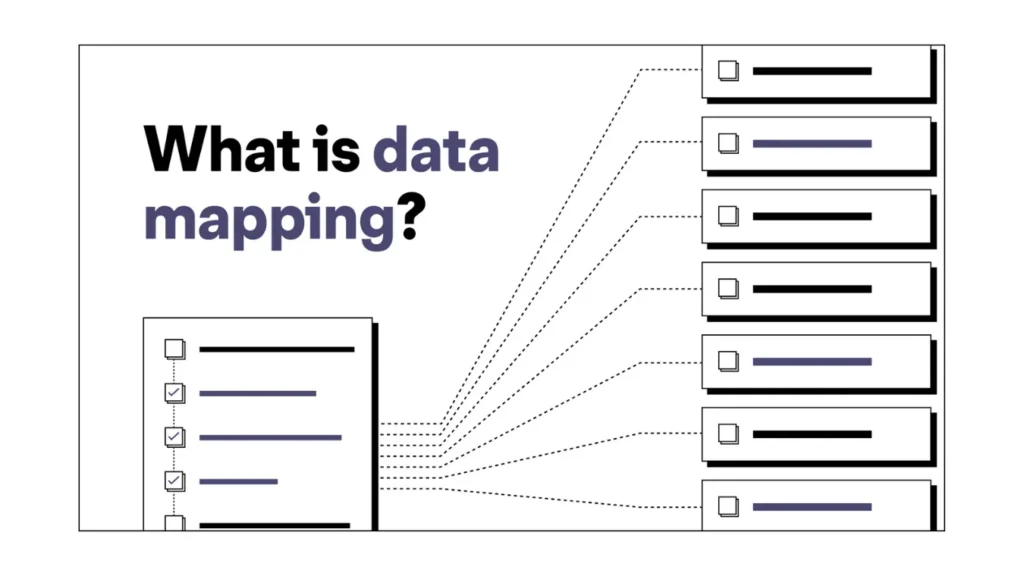
데이터 매핑의 핵심은 소스 구조 를 대상 구조.
테이블이나 파일에 대해서만 생각하는 대신 열, 필드, 관계 및 규칙 수준에서 작업합니다.
전체 맵은 일반적으로 다음을 지정합니다:
소스 개체(테이블, 뷰, 파일, API)
대상 개체(웨어하우스 테이블, 애플리케이션 엔터티, 보고서)
필드 수준 규칙: 직접 복사, 변환 및 조회
고유성, 필수 필드 및 유효한 범위와 같은 제약 조건
따라서 맵은 ETL, 통합 및 마이그레이션 프로세스가 반드시 따라야 하는 계약이 됩니다.
ETL 및 마이그레이션에서 데이터 매핑의 역할
ETL 중에 작업은 레코드를 추출하고, 변환을 적용하고, 결과를 로드합니다.
하지만 이러한 변환이 코드에만 머물러서는 안 됩니다.
비즈니스 사용자와 엔지니어가 함께 검토할 수 있는 문서화된 맵을 따라야 합니다.
마이그레이션 프로젝트에서 데이터 매핑은 모든 의사 결정의 기준이 됩니다:
여전히 중요한 레거시 필드
여러 소스를 단일 대상 모델로 병합하는 방법
이전 시스템에는 없었던 값을 배치할 위치
따라서 정확한 매핑을 통해 컷오버 시 예상치 못한 상황이 줄어들고 검증이 훨씬 쉬워집니다.
매핑 규칙 및 데이터 유형 유형
시나리오마다 다른 매핑 스타일이 필요합니다.
하나만 사용하는 경우는 거의 없습니다.
일반적인 매핑 스타일
직접 매핑: 호환되는 유형으로 소스에서 대상으로 값을 복사합니다.
변환 매핑: 수식, 구문 분석 또는 단위 변환을 적용합니다.
조회 또는 참조 매핑: 코드를 표준화된 값으로 바꿉니다.
조건부 매핑: 플래그 또는 범위에 따라 경로 레코드를 다르게 설정합니다.
이러한 패턴을 함께 사용하면 대부분의 통합 및 마이그레이션 요구 사항을 충족할 수 있습니다.
일반적인 데이터 유형 제품군
플랫폼에 따라 다양한 데이터 유형이 노출되지만, 네 가지 제품군이 가장 자주 등장합니다:
텍스트 데이터(문자열 및 문자)
숫자 데이터(정수 및 소수)
날짜 및 시간 데이터(타임스탬프 및 간격)
이진 또는 부울 데이터(참/거짓 플래그 및 원시 바이트)
유형이 일치하지 않으면 미묘한 버그가 발생하므로 매핑에는 예상되는 유형을 명시적으로 명시해야 합니다.
데이터 매핑을 구축하는 실용적인 단계
효과적인 데이터 매핑은 일회성 브레인스토밍 세션이 아닌 반복 가능한 방법을 따릅니다.
준비 및 소스 검색
먼저 소스를 프로파일링합니다:
권한 있는 시스템과 테이블을 식별합니다.
문서뿐만 아니라 실제 값을 검토하세요.
노트 범위, 형식, 널 패턴.
또한 도메인 전문가와 함께 비즈니스 의미를 명확히 하여 열 이름이 오해의 소지가 없도록 합니다.
소스-대상 규칙 설계
다음으로 매핑을 디자인합니다:
각 대상 필드를 하나 이상의 소스 필드에 정렬합니다.
어떤 변환 또는 조회가 필요한지 결정하세요.
누락되거나 선택 사항인 필드에 대한 기본값을 정의합니다.
가정과 엣지 케이스를 평이한 언어로 문서화하세요.
반복 작업을 수행하면서 기술적인 관점과 비즈니스 관점을 모두 일치시킬 수 있습니다.
맵 유효성 검사 및 유지 관리
마지막으로 지도를 테스트합니다:
실제 데이터를 사용하여 샘플 ETL 작업을 실행합니다.
개수, 합계 및 주요 관계를 비교하세요.
유효성 검사에서 숨겨진 문제가 발견되면 규칙을 조정하세요.
시스템은 진화하기 때문에 매핑을 정적인 스프레드시트가 아닌 살아 있는 아티팩트로 취급합니다.
거버넌스 및 GDPR을 위한 데이터 매핑
GDPR과 같은 규정에서는 조직이 개인 데이터의 위치와 시스템 사용 방식을 파악할 것을 요구합니다.
따라서 단순한 스토리지 다이어그램만으로는 충분하지 않습니다.
데이터 매핑이 도움이 됩니다:
개인 정보 또는 민감한 데이터가 포함된 필드 목록
애플리케이션 및 보고서에서 해당 필드가 이동하는 위치 표시
데이터 주체 액세스 요청 및 삭제 워크플로 지원
개인 식별자에서 매핑된 모든 필드와 대상을 가리킬 수 있으면 규제 업무를 자신 있게 처리할 수 있습니다.
SQL, Excel 및 전용 도구 사용
데이터 매핑을 시작하기 위해 복잡한 플랫폼이 필요하지는 않지만, 규모가 큰 팀은 나중에 전문화된 도구를 채택하는 경우가 많습니다.
SQL 및 매핑
SQL을 사용하면 매핑을 탐색하고 확인할 수 있습니다:
프로파일링 쿼리를 통해 실제 분포와 이상 징후를 확인할 수 있습니다.
JOIN은 향후 통합을 시뮬레이션합니다.
뷰는 영구 로드 전에 매핑된 구조를 구현할 수 있습니다.
따라서 SQL은 종종 매핑 결정을 위한 현미경이자 테스트 벤치 역할을 합니다.
Excel 및 경량 매핑 그리드
Excel은 여전히 매핑 캔버스로 잘 작동합니다:
소스 테이블용 열 하나, 소스 필드용 열 하나
대상 테이블용 열 하나, 대상 필드용 열 하나
변환 메모 및 데이터 유형에 대한 추가 열
나중에 ETL 개발자는 이 그리드를 작업과 스크립트로 변환합니다.
소규모 팀에서는 이 시트가 모든 사람이 읽을 수 있는 첫 번째 중앙 지도가 되는 경우가 많습니다.
Microsoft 에코시스템 옵션
Microsoft는 매핑 작업을 지원하는 도구도 제공합니다.
예를 들어, 파워 쿼리 를 사용하면 열 수준 변환을 시각적으로 정의할 수 있습니다. Azure 데이터 팩토리 또는 Synapse 파이프라인은 매핑된 흐름을 대규모로 구현합니다.
이러한 도구를 사용하는 경우에도 명확한 매핑 문서는 감사 및 문제 해결을 위해 로직을 투명하게 유지합니다.
백업 및 복구 관련 데이터 매핑
백업, 아카이브 및 복구 워크플로도 매핑에 따라 달라집니다.
데이터의 위치뿐만 아니라 백업 카탈로그가 실제 스토리지 위치 및 비즈니스 엔티티와 어떻게 연관되는지 알아야 합니다.
예를 들어 다음에서 내보낸 로그는 Amagicsoft 데이터 복구 매핑할 수 있습니다:
특정 장치 및 볼륨에 대한 복구 작업
비즈니스 소유자 또는 시스템에 대한 폴더
보존 또는 추가 확인을 위해 정책으로 지정하는 파일 유형
그 결과, 사고 대응자는 비즈니스 질문(“어떤 프로젝트 파일을 복구했습니까?”)에서 정확한 기술적 세부 사항으로 넘어갈 수 있습니다.
Windows 7/8/10/11 및 Windows Server를 지원합니다.