데이터 파이프라인
애드혹 스크립트에서 안정적인 데이터 흐름까지
많은 팀이 수동 내보내기, 일회성 SQL 쿼리, 스프레드시트 업로드로 시작합니다.
시간이 지남에 따라 이 패치워크는 느리고 깨지기 쉬우며 디버깅하기 어려워집니다.
데이터 파이프라인은 이러한 취약한 단계를 정의된 일련의 전송 및 변환 프로세스로 대체합니다.
데이터는 일정에 따라 또는 거의 실시간으로 검사하고 개선할 수 있는 규칙에 따라 경로를 따라 이동합니다.
데이터 파이프라인: 작업 정의
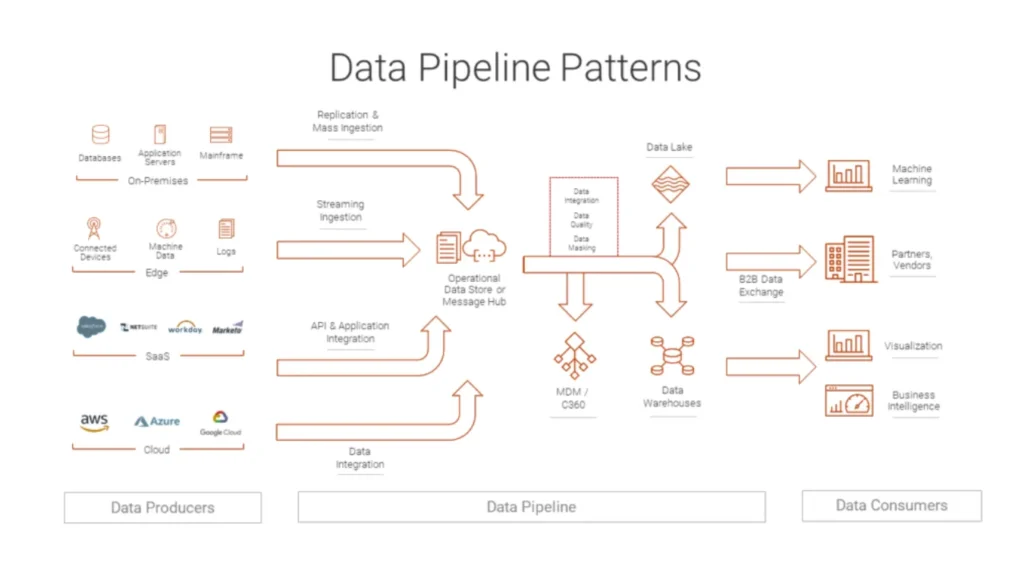
데이터 파이프라인은 데이터가 소스에서 목적지까지 이동하는 엔드투엔드 경로를 설명합니다.
이 경로를 따라 각 단계는 특정 작업을 수행하고 구조화된 결과물을 다음 단계로 넘깁니다.
파이프라인은 그럴 수 있습니다:
데이터베이스 및 로그에서 변경 이벤트 읽기
값 정리 및 표준화
참조 데이터로 기록 강화
창고, 호수 또는 검색 인덱스에 선별된 결과물 로드하기
수십 개의 고립된 작업 대신 하나의 조율된 흐름을 얻을 수 있습니다.
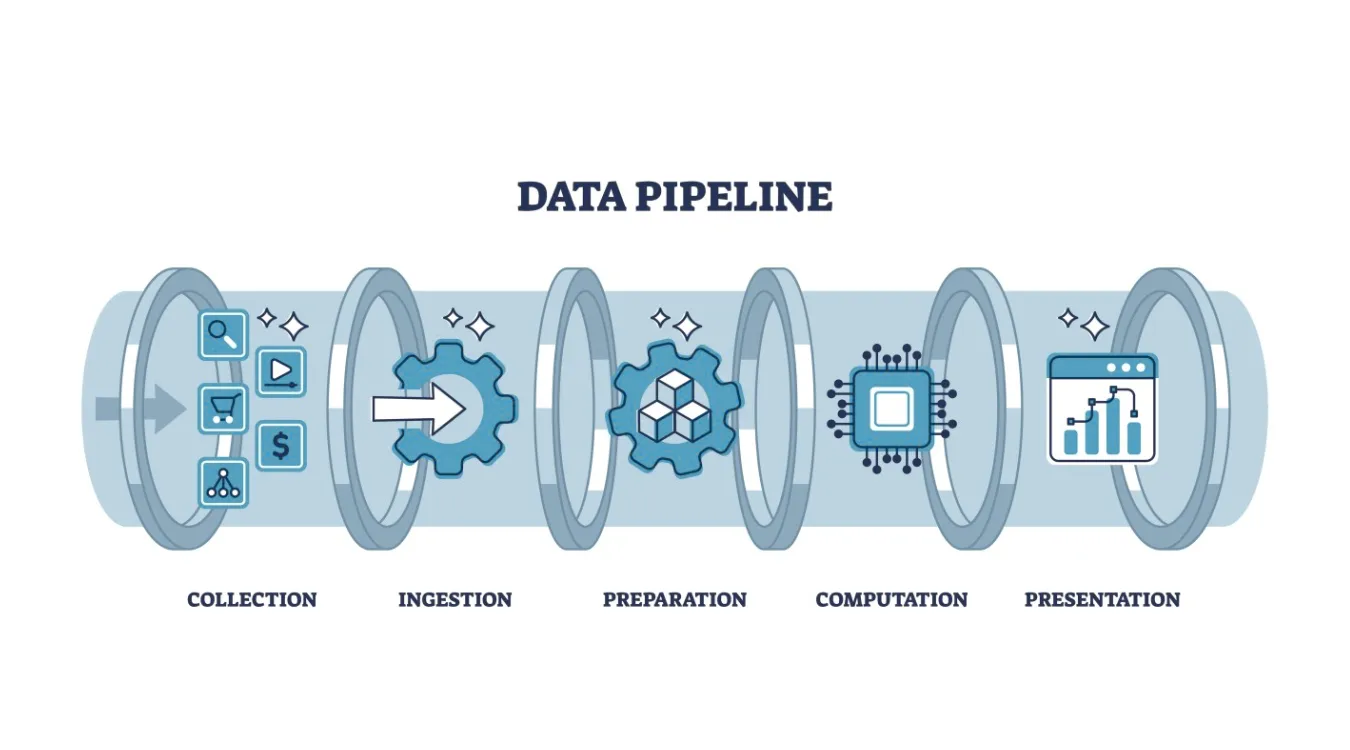
핵심 단계와 각 단계의 책임
대부분의 파이프라인은 도구가 다르더라도 동일한 기능의 빌딩 블록을 재사용합니다.
수집 및 캡처
수집 단계에서는 데이터를 생성하는 시스템(애플리케이션, 데이터베이스, API, 디바이스 또는 파일)에 연결합니다.
새 레코드를 메시지 대기열, 스테이징 테이블 또는 개체 저장소와 같은 내구성 있는 랜딩 영역으로 복사하거나 스트리밍합니다.
여기서 주요 목표는 다음과 같습니다:
조용한 데이터 손실 방지
급증하는 볼륨을 우아하게 처리
필요할 때 재생할 수 있도록 원본 기록 보존
변환, 검증 및 강화
변환 단계에서는 원시 이벤트를 분석이 가능한 데이터로 변환합니다.
일반적인 작업:
유형, 표준 시간대 및 필드 이름 정규화하기
유효성 검사 규칙 적용 및 유효하지 않은 행 삭제 또는 격리
스트림 또는 테이블을 조인하여 컨텍스트 추가(고객, 제품, 지역)
합계, 평균, 플래그 등의 메트릭 계산하기
모든 보고서 내부가 아닌 이 단계에서 품질을 강화하여 다운스트림 작업을 보호할 수 있습니다.
로드 및 제공
마지막으로 파이프라인은 정리된 데이터를 대상 시스템으로 로드합니다:
BI 및 SQL 분석을 위한 데이터 웨어하우스
유연한 대용량 스토리지를 위한 데이터 레이크
로그 및 이벤트 탐색을 위한 검색 인덱스
머신 러닝 및 애플리케이션을 위한 기능 저장소 또는 API
그러면 대시보드, 알림 및 도구는 이러한 일관되고 문서화된 구조에서 읽을 수 있습니다.
파이프라인 스타일: 배치, 스트리밍 및 혼합 모델
워크로드마다 다른 파이프라인 스타일이 필요합니다.
배치 파이프라인 종종 매 시간 또는 매일 일정에 따라 실행됩니다.
재무 요약, 일일 백업, 규제 보고서 등에 적합합니다.스트리밍 파이프라인 이벤트가 도착하는 대로 지속적으로 처리합니다.
모니터링, 이상 징후 감지, 실시간에 가까운 대시보드를 지원합니다.마이크로 배치 파이프라인 지연 시간과 단순성 사이의 균형을 위해 짧은 시간 창을 그룹화합니다.
많은 조직에서 시간에 민감한 메트릭은 스트리밍으로, 기록 처리량이 많은 메트릭은 배치로 처리하는 하이브리드 디자인을 운영하고 있습니다.
안정성, 복구 및 재처리
데이터 파이프라인은 장애 발생 시 예측 가능한 방식으로 작동할 때만 가치를 더합니다.
중복이나 손상 없이 작업을 다시 시작하고 재처리할 수 있도록 설계합니다.
중요한 관행:
체크포인트 또는 오프셋을 사용하여 스트림과 파일의 진행 상황을 추적하세요.
변환 유지 idempotent, 로 설정되어 있으므로 재실행해도 동일한 결과가 나타납니다.
원시 입력을 재생 가능한 형식으로 저장하여 버그 수정 후 백필을 지원합니다.
나중에 검사할 수 있도록 자세한 오류 로그와 거부된 행을 캡처하세요.
이러한 규칙을 준수하면 장애 복구는 위기 대응이 아닌 일상적인 유지 관리처럼 보입니다.
통합 가시성 및 데이터 품질 신호
시스템 상태와 데이터 품질 모두에 대한 가시성이 필요합니다.
이 기능이 없으면 파이프라인이 조용히 잘못된 숫자를 생성할 수 있습니다.
유용한 지표 및 확인 사항:
각 단계의 기록 입력과 기록 출력
수집 및 변환 전반에 걸친 처리 지연 시간
이유별 거부 또는 격리된 행 수
널 요금 또는 값 범위와 같은 간단한 프로파일링 메트릭
업스트림 시스템에서 필드 변경 시 스키마 드리프트 감지
이러한 신호를 기반으로 구축된 대시보드는 병목 현상, 오류 또는 품질 저하가 나타나는 위치를 보여줍니다.
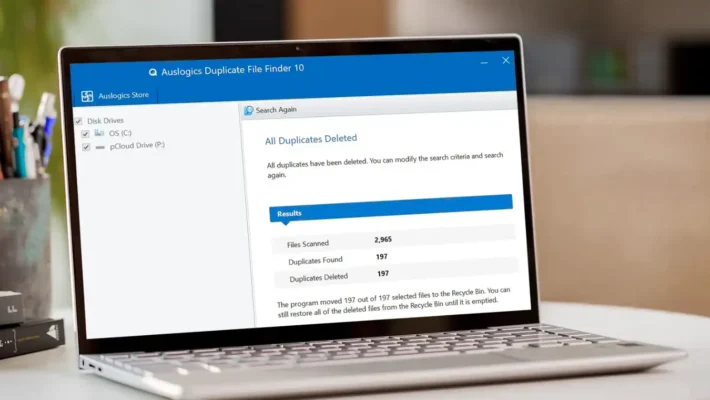
파이프라인 내부의 데이터 복구 로그
백업 및 복구 워크플로 파이프라인의 이점도 누릴 수 있습니다.
로그를 여러 머신에 흩어져 두는 대신 데이터 소스로 취급할 수 있습니다.
예를 들어 다음과 같은 경우 Amagicsoft 데이터 복구 스캔 및 복구를 실행할 수 있습니다:
작업 로그 및 요약을 파일 또는 데이터베이스로 내보내기
이러한 레코드를 중앙 파이프라인으로 수집
장치 ID, 크기, 기간, 결과 등 일관된 필드로 변환하세요.
결과를 웨어하우스 또는 대시보드에 로드합니다.
그런 다음 팀은 복구 성공률을 추적하고, 장애의 패턴을 감지하고, 실제 증거를 바탕으로 용량을 계획합니다.
Windows 7/8/10/11 및 Windows Server를 지원합니다.