データパイプライン
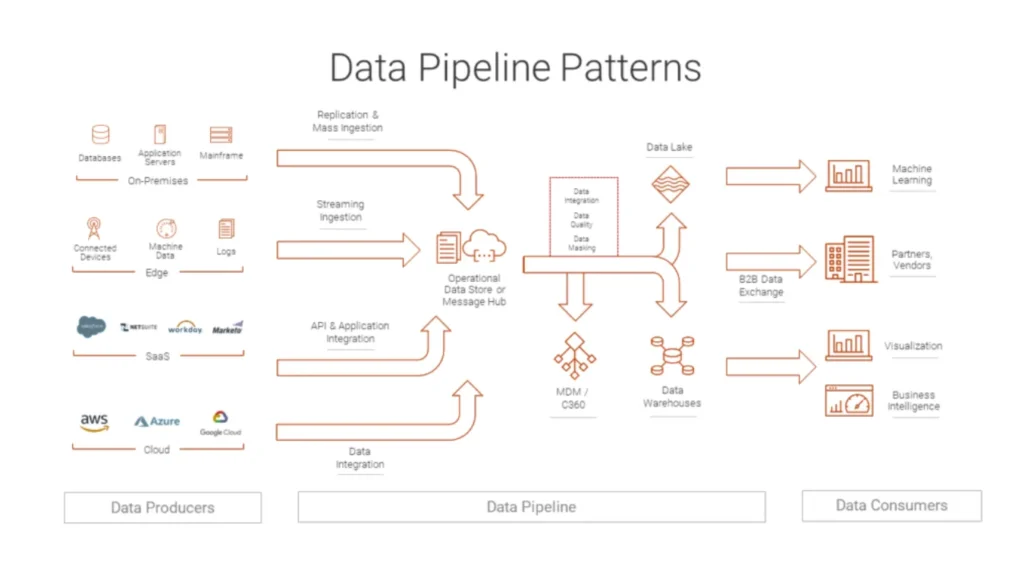
アドホック・スクリプトから信頼できるデータフローへ
多くのチームは、手動のエクスポート、単発のSQLクエリ、スプレッドシートのアップロードから始めている。.
時間が経つにつれて、このパッチワークは遅く、もろくなり、デバッグが難しくなる。.
データパイプラインは、そのような脆弱なステップを、定義されたトランスポートと変換プロセスのシーケンスに置き換える。.
データは、あなたが検査し、改善することができるルールの下で、スケジュールに沿って、またはほぼリアルタイムでパスに沿って移動する。.
データパイプライン:作業定義
データパイプラインは、データがソースから宛先までたどるエンド・ツー・エンドの経路を記述する。.
そのルート上で、各ステージは特定のタスクを実行し、構造化された出力を次のステージに渡す。.
パイプラインはそうかもしれない:
データベースやログから変更イベントを読み取る
数値のクリーン化と標準化
参照データで記録を充実させる
キュレーションされたアウトプットをウェアハウス、レイク、検索インデックスにロードする。
何十もの孤立した仕事の代わりに、1つの調整された流れが得られる。.
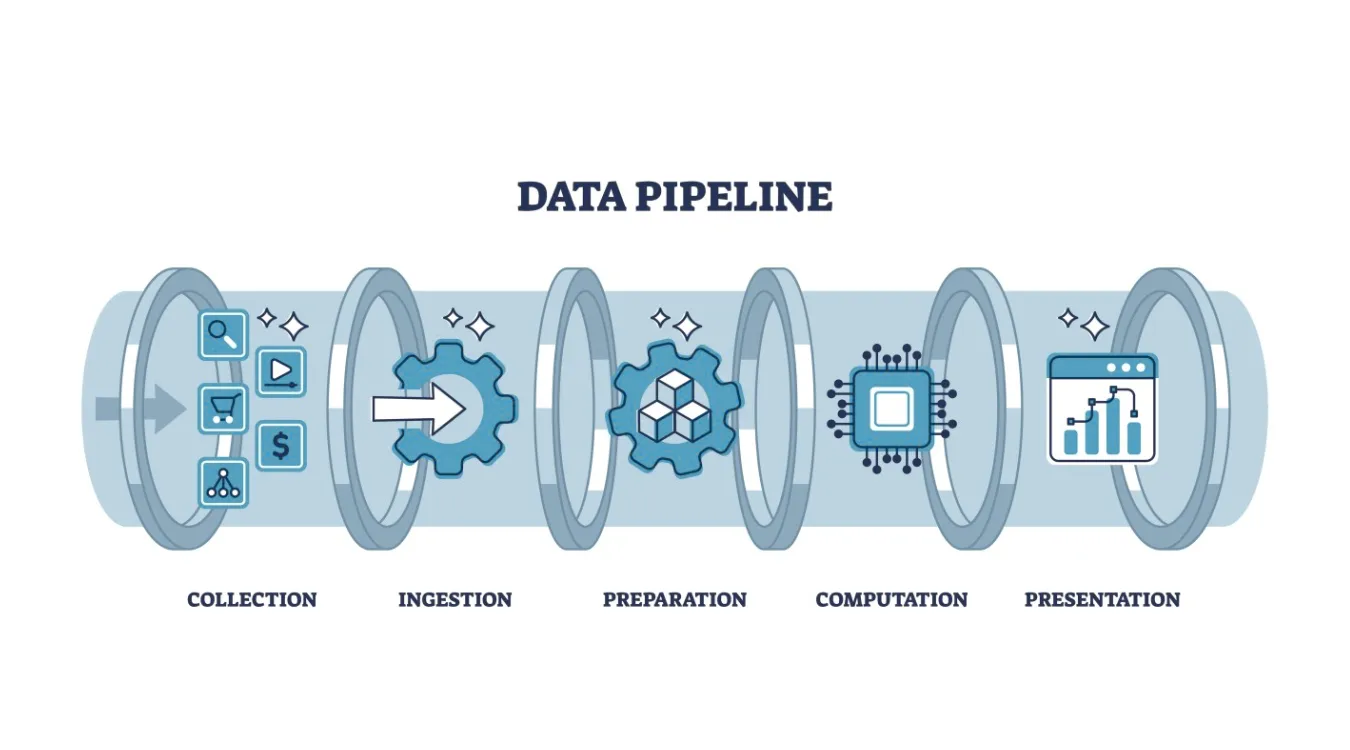
コア・ステージとその責任
ほとんどのパイプラインは、ツールが異なっても、同じ機能構成ブロックを再利用する。.
インジェストとキャプチャ
インジェスト・ステージは、アプリケーション、データベース、API、デバイス、ファイルなど、データを生成するシステムに接続する。.
新しいレコードを、メッセージキュー、ステージングテーブル、オブジェクトストレージなどの耐久性のあるランディングゾーンにコピーまたはストリームする。.
ここでの重要な目標
サイレント・データ・ロスを避ける
ボリュームの急増を優雅に処理する
必要なときに再生できるよう、オリジナルの記録を保存
変革、検証、そして充実させる
変換ステージは、生のイベントを分析可能なデータに変換する。.
代表的な仕事
タイプ、タイムゾーン、フィールド名の正規化
検証ルールを強制し、無効な行を削除または隔離する。
ストリームまたはテーブルを結合してコンテキストを追加(顧客、製品、地域)
合計、平均、フラグなどのメトリクスの計算
各レポートの内部ではなく、このステップで品質を強制することで、下流の仕事を守ることができる。.
ロード&サーブ
最後に、パイプラインはクリーン化されたデータをターゲットシステムにロードする:
BIおよびSQL分析のためのデータウェアハウス
大規模で柔軟なストレージのためのデータレイク
ログとイベント探索のための検索インデックス
機械学習やアプリケーションのためのフィーチャーストアやAPI
ダッシュボード、アラート、ツールは、これらの一貫した文書化された構造から読み取ることができる。.
パイプラインのスタイル:バッチ、ストリーミング、混合モデル
ワークロードが異なれば、パイプラインのスタイルも異なる。.
バッチ・パイプライン 多くの場合、1時間または1日ごとにスケジュールされる。.
財務サマリー、日々のバックアップ、規制当局の報告書などに適している。.ストリーミング・パイプライン 到着したイベントを連続的に処理する。.
監視、異常検知、ほぼリアルタイムのダッシュボードをサポートする。.マイクロバッチパイプライン をグループ分けして、待ち時間とシンプルさのバランスをとる。.
多くの組織では、ハイブリッド設計を採用している。時間に敏感なメトリクスにはストリーミングを使用し、重い履歴処理にはバッチを使用する。.
信頼性、回収、再処理
データ・パイプラインは、失敗時に予測可能な動作をして初めて価値を高める。.
ジョブが重複したり破損したりすることなく、再起動や再処理ができるように設計するのだ。.
重要な練習
チェックポイントやオフセットを使って、ストリームやファイルの進行状況を追跡する。.
変形を維持する べきべき, だから再放送しても同じ結果になる。.
生の入力を再生可能な形式で保存し、バグ後の埋め戻しをサポートする。.
詳細なエラーログや拒否された行を記録し、後で確認することができます。.
これらのルールに従えば、故障からの回復は危機的な作業ではなく、日常的なメンテナンスのように見える。.
観測可能性とデータ品質シグナル
システムの健全性とデータ品質の両方を可視化する必要がある。.
それがなければ、パイプラインはひっそりと間違った数字を出すことになる。.
便利なメトリクスとチェック:
各段階での記録インと記録アウト
インジェストと変換にまたがる処理待ち時間
拒否または隔離された行の数(理由別
ヌル率や値域などの単純なプロファイリング指標
上流システムがフィールドを変更した場合のスキーマ・ドリフト検出
これらのシグナルに基づいて作られたダッシュボードは、ボトルネック、エラー、品質の後退がどこに現れるかを示す。.
パイプライン内のデータ復旧ログ
バックアップ 回復ワークフロー パイプラインの恩恵も受ける。.
ログをマシンに散在させたままにするのではなく、データソースとして扱うことができる。.
例えば Amagicsoftデータ復旧 スキャンとリカバリーを実行することができます:
ジョブログとサマリーをファイルまたはデータベースにエクスポート
これらのレコードを中央パイプラインに取り込む
一貫性のあるフィールドに変換:機器ID、サイズ、期間、結果
結果をウェアハウスやダッシュボードに読み込む
チームは、復旧成功率を追跡し、障害のパターンを検出し、実際の証拠に基づいてキャパシティを計画する。.
Windows 7/8/10/11およびWindows Serverをサポート。.