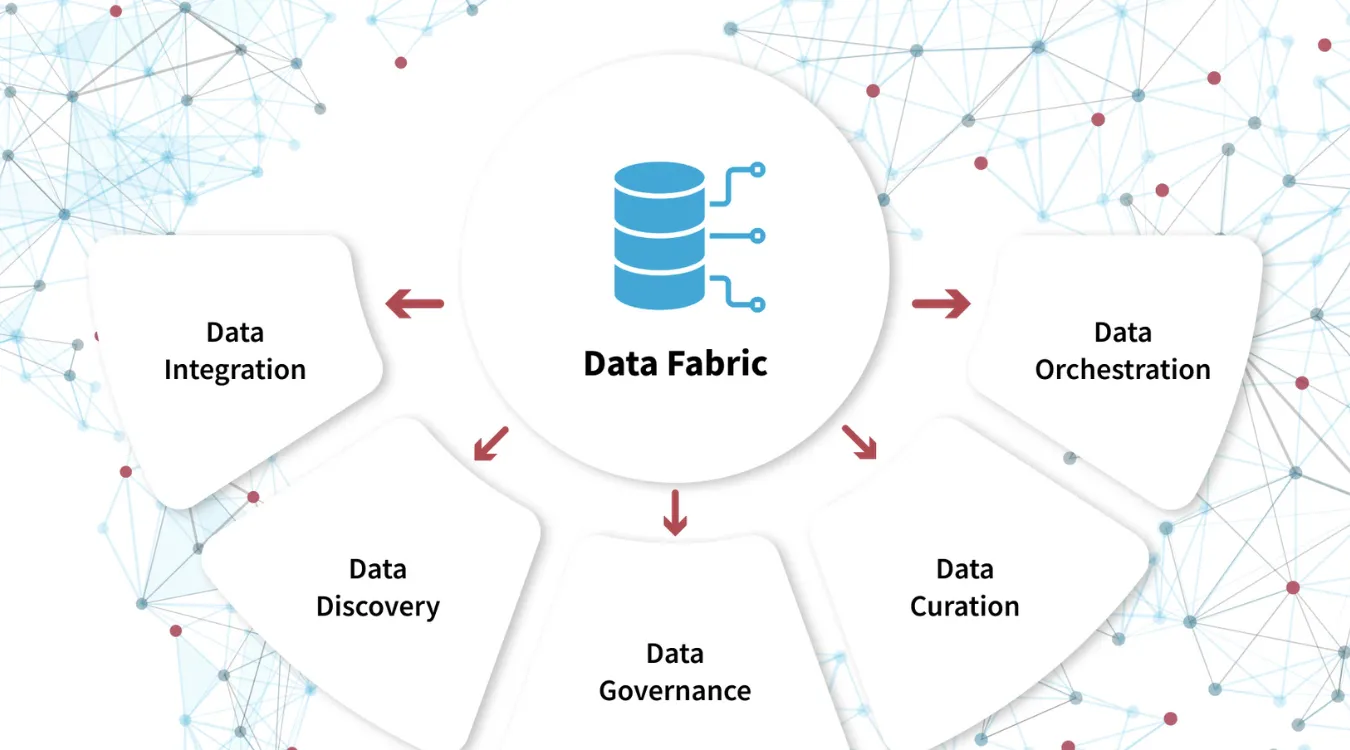
Daten-Gewebe

Hybrider Speicher ohne Spaghetti
Die meisten Unternehmen kombinieren heute lokale Server, Cloud-Buckets, SaaS-Datenbanken und archivierte Snapshots.
Ingenieure verknüpfen sie mit einmaligen Skripten, benutzerdefinierten ETL-Aufträgen und vielen Dashboards.
Schließlich verwandelt sich die Umwelt in ein Spaghetti-Diagramm, das niemand vollständig versteht.
A Datenstruktur löst dieses Problem, indem es als einheitliche Ebene über all diese Speicherressourcen fungiert, unabhängig davon, ob sie sich vor Ort oder in mehreren Clouds befinden.
Definition von Data Fabric in modernen Architekturen
Eine Data Fabric ist ein architektonischer Ansatz, kein einzelnes Produkt.
Die Anbieter implementieren es auf unterschiedliche Weise, doch die Kernidee bleibt gleich: eine logische Schicht zu schaffen, die Daten über hybride und Multi-Cloud-Standorte hinweg verbindet, sichert und verwaltet.
Anstatt alles in ein riesiges Lagerhaus zu kopieren, bauen Sie:
Eine einheitliche Methode zum Auffinden von Datenbeständen
Eine Reihe von gemeinsamen Diensten (Sicherheit, Governance, Transformation)
Eine virtuelle Ansicht, die den meisten Verbrauchern die physische Komplexität vorenthält
Aufgrund dieser Abstraktion können Anwendungen und Analysetools Abfragen über die Fabric durchführen, während die Fabric orchestriert, wo und wie auf den zugrunde liegenden Speicher zugegriffen wird.
Schlüsselfunktionen in einer Data Fabric verwoben
Obwohl es unterschiedliche Implementierungen gibt, bieten erfolgreiche Fabrics in der Regel mehrere Funktionen.
Vereinheitlichter Zugang und Virtualisierung
Eine Fabric stellt Daten über gemeinsame Schnittstellen wie SQL-Endpunkte, APIs oder Kataloge zur Verfügung.
Es kann Tabellen und Objekte aus vielen Systemen so darstellen, als gehörten sie zu einem logischen Raum.
Folglich konzentrieren sich Analysten auf Datensätze und Richtlinien statt auf Verbindungsstrings und Anmeldedaten für jedes Silo.
Integrierte Governance und Sicherheit
Sicherheit und Governance sind oft auf verschiedene Tools verteilt.
Eine Datenstruktur zentralisiert:
Zugangskontrolle und Richtlinien
Maskierungs- und Tokenisierungsregeln
Nachverfolgung von Herkunft und Nutzung
So können Prüfer nachvollziehen, wie sich sensible Felder bewegen, und Administratoren können einheitliche Regeln anwenden, ohne jede Pipeline neu schreiben zu müssen.
Intelligente Bewegung und Caching
Die Fabric entscheidet, wann Daten verschoben werden, wann sie an Ort und Stelle verbleiben und wann die Ergebnisse zwischengespeichert werden.
Manchmal werden Abfragen dorthin geschickt, wo bereits Daten vorhanden sind.
Manchmal werden die Ergebnisse in der Nähe der Benutzer oder in der Nähe schwerer Verarbeitungsmaschinen erzielt.
Durch diese Flexibilität werden unnötige Kopien vermieden und gleichzeitig die Anforderungen an Leistung und Lokalisierung erfüllt.
Data Fabric im Verhältnis zu Data Mesh und ETL
Da sich die Schlagworte überschneiden, ist es hilfreich, sie direkt zu vergleichen.
Architektur und Eigentümerschaft Ansicht
Datengewebe konzentriert sich auf eine einheitliche technische Ebene und gemeinsame Dienste.
Datengitter legt den Schwerpunkt auf Domain Ownership, Produktdenken und föderale Governance.
Sie können in der Tat ein Netz von Domänendatenprodukten auf einer Fabric betreiben, die Konnektivität, Kataloge und Sicherheit bietet.
Bewegung und Transformation Ansicht
ETL ist auch innerhalb eines Gewebes wichtig.
Pipelines extrahieren, transformieren und laden, wenn Sie dauerhaft abgeleitete Datensätze oder leistungsoptimierte Speicher benötigen.
Allerdings fügt der Stoff:
Erkundung vorhandener Daten, bevor Sie neue Datenströme erstellen
Virtualisierter Zugriff auf Abruf, bei dem das Kopieren optional wird
Globale Richtlinien, die ETL-Aufträge einhalten müssen
Daher wird ETL zu einem Werkzeug innerhalb eines umfassenderen Gefüges und ist nicht die einzige Möglichkeit, Daten zu bewegen.
Schnellvergleichstabelle
| Aspekt | Daten-Gewebe | Datengeflecht | Klassisch ETL |
|---|---|---|---|
| Hauptschwerpunkt | Einheitliche Datenschicht und Dienste | Domänenbesitz & Datenprodukte | Bewegung und Transformation |
| Umfang | Hybride / Multi-Cloud-Konnektivität | Organisationsstruktur und Zuständigkeiten | Spezifische Pipelines |
| Standort der Daten | Mischung aus vor Ort und bewegt | Abhängig von den Entscheidungen des Bereichs | Meistens auf Zielscheiben verschoben |
| Governance | Zentrale Plattformfunktionen | Domänenübergreifend im Verbund | Oft Pipeline für Pipeline |
Wenn eine Data Fabric am meisten hilft
Eine Datenstruktur eignet sich für Umgebungen mit echter Vielfalt und Größe.
Es schafft Mehrwert, wenn:
Daten sind über mehrere Clouds und lokale Speicher verteilt
Teams verwenden viele Tools, die alle überlappende Datensätze benötigen
Sicherheits- und Compliance-Vorschriften müssen einheitlich gelten
Das Kopieren großer Mengen zwischen Plattformen ist teuer geworden
Umgekehrt profitiert ein kleines Unternehmen mit einer einzigen primären Datenbank und einigen wenigen Berichten möglicherweise nicht sehr von der Komplexität.
Auswirkungen auf Sicherung, Wiederherstellung und Ausfallsicherheit von Daten
Vom Standpunkt des Datenschutzes aus betrachtet, verändert ein Fabric die Art und Weise, wie man über Ausfallsicherheit denkt.
Sie schützen nicht mehr nur einen zentralen Speicher, sondern eine vernetzte Schicht aus vielen Speichern, Snapshots und Repliken.
Ein auf die Struktur abgestimmter Schutzansatz:
Verfolgt, wo wichtige Datensätze plattformübergreifend gespeichert sind
Koordiniert Backups und Aufbewahrungsrichtlinien aus einer Sicht
Nutzt Kataloge und Metadaten, um die richtige Version am richtigen Ort wiederherzustellen
Wenn Teile des Netzes ausfallen oder die Speicher beschädigt werden, können Tools wie Amagicsoft Datenrettung noch bei der Lautstärke helfen.
Die Metadaten und die Abstammung der Fabric beschleunigen jedoch die Aufgabe, die wichtigen Kopien zu finden und sie wiederherzustellen.
Unterstützt Windows 7/8/10/11 und Windows Server.