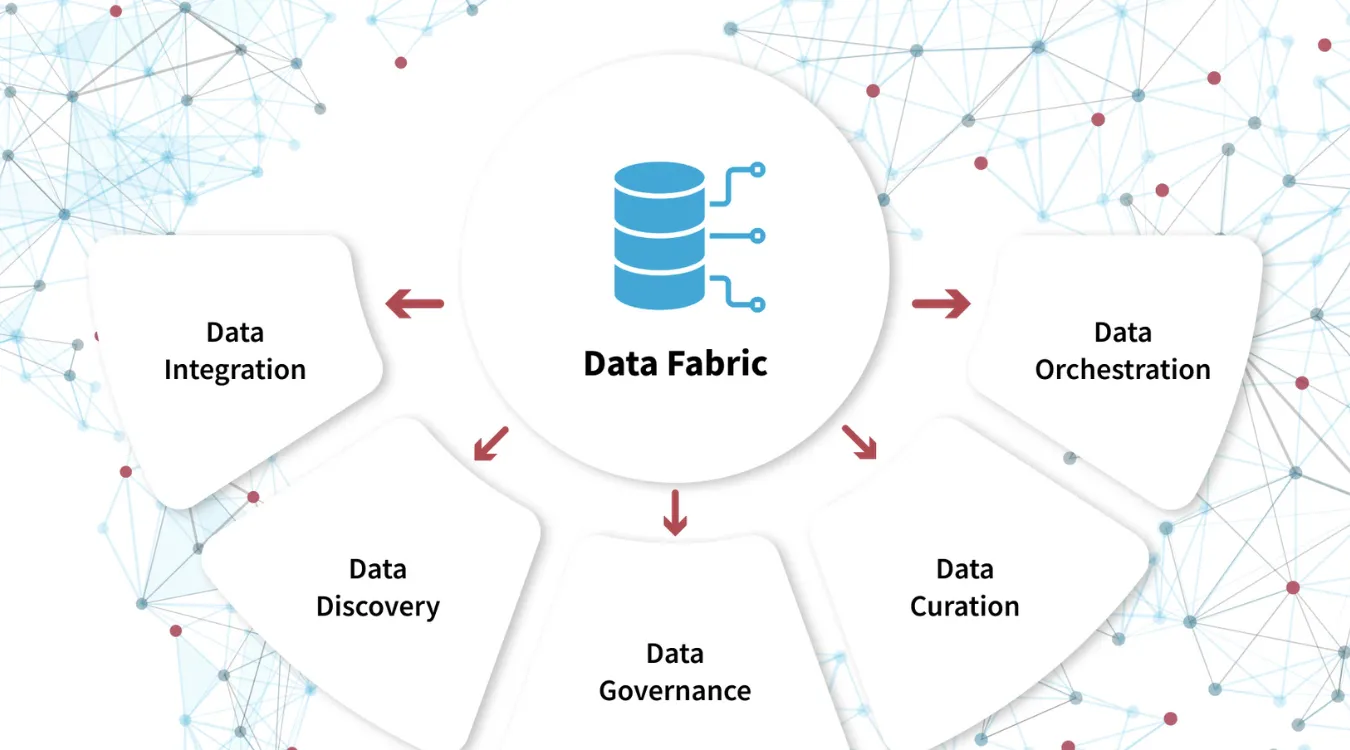
La structure des données (Data Fabric)

Le stockage hybride sans les spaghettis
La plupart des entreprises mélangent aujourd'hui des serveurs locaux, des baquets dans le nuage, des bases de données SaaS et des instantanés archivés.
Les ingénieurs les relient par des scripts ponctuels, des tâches ETL personnalisées et de nombreux tableaux de bord.
L'environnement finit par se transformer en un diagramme de spaghettis que personne ne comprend entièrement.
A tissu de données résout ce problème en agissant comme une couche unifiée sur toutes ces ressources de stockage, qu'elles se trouvent sur site ou dans plusieurs nuages.
Définir la structure des données dans les architectures modernes
Une structure de données est une approche architecturale et non un produit unique.
Les fournisseurs le mettent en œuvre de différentes manières, mais l'idée de base reste la même : créer une couche logique qui connecte, sécurise et gère les données sur des sites hybrides et multiclouds.
Au lieu de tout copier dans un entrepôt géant, vous construisez :
Une façon cohérente de découvrir les ressources de données
Un ensemble de services partagés (sécurité, gouvernance, transformation)
Une vision virtuelle qui cache la complexité physique à la plupart des consommateurs
Grâce à cette abstraction, les applications et les outils d'analyse effectuent des requêtes par l'intermédiaire de la structure, tandis que celle-ci orchestre le lieu et la manière d'accéder au stockage sous-jacent.
Capacités clés intégrées dans une structure de données
Bien que les implémentations diffèrent, les tissus performants offrent généralement plusieurs fonctionnalités.
Accès unifié et virtualisation
Une structure expose les données par le biais d'interfaces communes, telles que des points d'extrémité SQL, des API ou des catalogues.
Il peut présenter des tables et des objets provenant de plusieurs systèmes comme s'ils appartenaient à un seul espace logique.
Par conséquent, les analystes se concentrent sur les ensembles de données et les politiques plutôt que sur les chaînes de connexion et les informations d'identification pour chaque silo.
Gouvernance et sécurité intégrées
La sécurité et la gouvernance sont souvent dispersées entre les différents outils.
Une structure de données centralise :
Contrôle d'accès et politiques
Règles de masquage et de symbolisation
Suivi de la lignée et de l'utilisation
Ainsi, les auditeurs peuvent retracer la manière dont les champs sensibles sont déplacés et les administrateurs peuvent appliquer des règles cohérentes sans avoir à réécrire chaque pipeline.
Déplacement et mise en cache intelligents
La structure décide quand déplacer les données, quand les laisser en place et quand mettre les résultats en cache.
Parfois, il envoie des requêtes là où les données se trouvent déjà.
Parfois, il matérialise les résultats à proximité des utilisateurs ou des moteurs de traitement lourds.
Cette flexibilité permet de réduire les copies inutiles tout en respectant les exigences de performance et de localité.
Data Fabric en relation avec Data Mesh et ETL
Les mots à la mode se chevauchant, il est utile de les comparer directement.
Vue de l'architecture et de la propriété
Tissu de données se concentre sur une couche technique unifiée et des services partagés.
Maillage de données met l'accent sur la propriété du domaine, la réflexion sur le produit et la gouvernance fédérée.
Il est en effet possible de faire fonctionner un maillage de produits de données de domaine au-dessus d'une structure qui assure la connectivité, les catalogues et la sécurité.
Vue du mouvement et de la transformation
L'ETL a encore de l'importance au sein d'une structure.
Les pipelines extraient, transforment et chargent lorsque vous avez besoin d'ensembles de données dérivées permanentes ou de magasins aux performances optimisées.
Cependant, le tissu ajoute :
Découverte des données existantes avant de créer de nouveaux flux
Accès à la demande, virtualisé, où la copie devient facultative
Politiques globales que les jobs ETL doivent respecter
Par conséquent, l'ETL devient un outil parmi d'autres au sein d'un tissu plus large, et non plus la seule façon dont les données circulent.
Tableau de comparaison rapide
| Aspect | La structure des données (Data Fabric) | Maille de données | ETL classique |
|---|---|---|---|
| Principaux points d'attention | Couche de données et services unifiés | Propriété du domaine et produits de données | Mouvement et transformation |
| Champ d'application | Connectivité hybride / multi-cloud | Structure organisationnelle et responsabilités | Pipelines spécifiques |
| Localisation des données | Mélange de produits en place et de produits déplacés | Dépend des décisions prises dans le domaine | Principalement déplacé vers les objectifs |
| Gouvernance | Capacités de la plate-forme centrale | Fédéré entre les domaines | Souvent pipeline par pipeline |
Quand une structure de données est la plus utile
Un tissu de données s'adapte à des environnements d'une diversité et d'une ampleur réelles.
Il apporte une valeur ajoutée lorsque :
Les données sont réparties entre plusieurs nuages et entrepôts sur site.
Les équipes utilisent de nombreux outils qui ont tous besoin d'ensembles de données qui se chevauchent.
Les règles de sécurité et de conformité doivent être appliquées de manière cohérente
La copie de gros volumes entre plates-formes est devenue coûteuse
À l'inverse, une petite organisation disposant d'une seule base de données principale et de quelques rapports peut ne pas tirer grand profit de cette complexité.
Impact sur la sauvegarde, la récupération et la résilience des données
Du point de vue de la protection des données, un tissu change la façon de concevoir la résilience.
Vous ne protégez plus un seul magasin central, mais une couche interconnectée de plusieurs magasins, snapshots et répliques.
Une approche de protection adaptée au tissu :
Suivi de l'emplacement des ensembles de données critiques sur les différentes plates-formes
Coordonne les sauvegardes et les politiques de conservation à partir d'un seul point de vue
Utilise les catalogues et les métadonnées pour récupérer la bonne version au bon endroit.
Lorsque des parties du tissu tombent en panne ou que des données sont corrompues, des outils tels que Amagicsoft Récupération de données Le niveau de volume peut encore aider.
Toutefois, les métadonnées et le lignage du tissu accélèrent la tâche consistant à localiser les copies importantes et à déterminer l'endroit où les restaurer.
Prend en charge Windows 7/8/10/11 et Windows Server.