データ検証
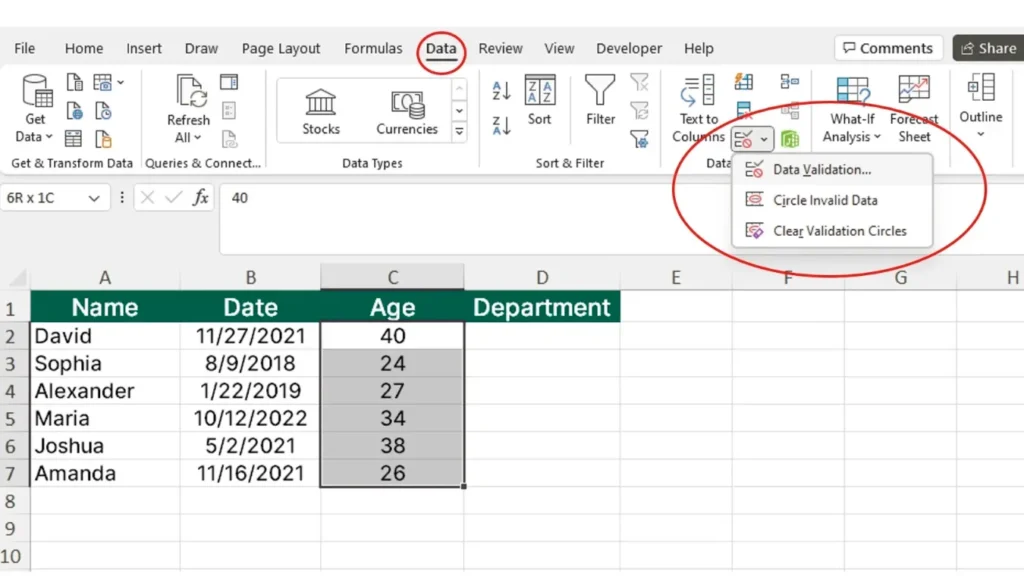
データ品質の問題は入力から始まる
多くのシステムは、ディスクやアプリケーションが壊れるずっと前に故障する。.
フォームが間違った日付を受け取ったり、スクリプトが無効なIDを書き込んだり、バックアップジョブが不完全な値で “成功 ”を記録したりすると、静かに失敗する。.
こうした小さなエラーは、レポートやダッシュボード、さらにはリカバリーのワークフローにまで及ぶ。.
データ・バリデーションは、各値がコア・データセットに入る前に、明確な技術的ルールと照らし合わせてチェックすることで、そのようなドリフトを阻止する。.
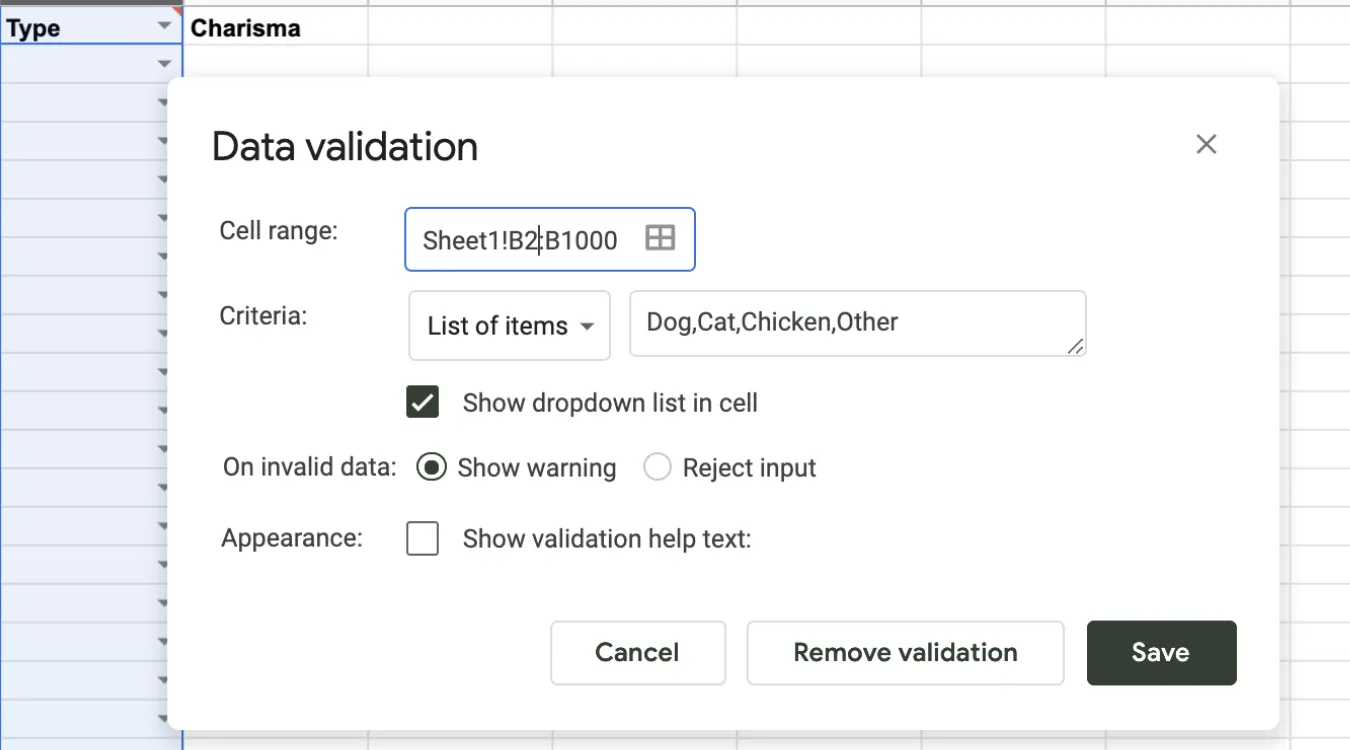
データ検証の核となる考え方
データの検証とは、入力されたデータの正確性、完全性、一貫性を、保管や処理の前にチェックすることである。.
これらのチェックは、UI、API、ETLパイプライン、または直接データベースで実行できる。.
典型的な目標
明らかに無効な値を拒否する
疑わしい記録や不完全な記録にフラグを立てる
フォーマットを予測可能なパターンに正規化する
悪い入力から下流のシステムを守る
すべての価値観を信頼するのではなく、システムはそれぞれの価値観に挑戦し、管理された方法でそれを受け入れたり、修正したり、拒否したりする。.
バリデーション・ルールの種類とその役割
一つのルールに頼ることはほとんどない。.
ほとんどの実装では、異なるリスクをカバーするために、複数の検証タイプを組み合わせている。.
| バリデーション・タイプ | フォーカス | 簡単な例 |
|---|---|---|
| フォーマット / 構文 | 値の構造 | Eメールには“@”とドメインが含まれていること |
| レンジ/リミット | 数値または日付の境界 | 年齢0歳以上120歳未満 |
| 参照 / 検索 | 他のデータとの関係 | 既存の顧客IDを使用した注文 |
| ビジネス・ロジック | ドメイン固有の条件 | 終了日が開始日の後になる |
これらのルールは、ID、タイムスタンプ、金額といった重要なフィールドのセーフティネットを形成する。.
バリデーションの居場所:UI、サービス、ストレージ
頑健なシステムは、単一の検証層に依存しない。.
フローの複数のポイントでチェックを組み合わせるのだ。.
ユーザーインターフェース
フォームには必須フィールドとフォーマットがあります。.
ドロップダウンリストは、選択肢を有効なものに限定します。.
リアルタイムヒントは、ユーザーを有効な入力に誘導する。.
単純なミスは早い段階で減らせるが、自動化やスクリプトがそれを回避できるため、UIはまだ信頼されていないものとして扱われる。.
APIとサービス
RESTまたはRPCエンドポイントは、ペイロードの構造と型を検証する。.
サービスはビジネスルールと許可を適用する。.
セントラル・ロジックは、クライアント間で一貫した動作を維持する。.
このレイヤーは、新しいフロントエンドが登場しても内部データを保護する。.
データベースとETLの仕事
データベース制約、トリガー、チェック条項は、厳格なルールを強制する。.
ETLプロセスは、インポートされたファイルを検証し、拒否された行をログに記録する。.
バッチジョブで集計を照合し、データの欠落や重複を検出する。.
このより深い層は、破損した値が最も重要な長期保存を保護する。.
SQLとストレージ・システムにおけるバリデーションの実装
リレーショナル・データベースは、データの近くで検証するための強力なツールを提供する。.
アプリケーションレベルのチェックと組み合わせることで、カバレッジを高めることができる。.
一般的なメカニズム
データタイプ一般的な文字列ではなく、最も特殊な型(DATE、INT、DECIMAL)を使用します。.
チェック制約列の範囲やパターンを強制する。.
FOREIGN KEY制約テーブル間の有効な関係を保証する。.
UNIQUE制約キーや識別子の重複を防ぐ。.
などのツールをサポートするログおよびバックアップカタログテーブルの場合。 Amagicsoftデータ復旧, これらの制約により、監査やインシデント分析時に、ジョブ記録、パス、タイムスタンプの信頼性が保たれます。.